Excerpt: Query Power
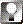 |
Preventing Query Overload If you use queries frequently, your ~/queries folder can fill up pretty fast. Even though it's great that queries are automatically saved for you, in reality you're not going to need to revisit most of the queries you create. For this reason, queries will self-destruct in seven days by default. If you plan on using a query again in the future, be sure to uncheck the Temporary checkbox in the extra options section of the Query dialog. |
|
Search the Trash By default, queries won't find files that have been moved to the Trash. If you do want trashed files to show up in the query results window, click the Include Trash checkbox. Note that the Trash is not excluded by default when you run queries from the command line. |
All Files and Folders versus Individual Filetypes
The default query is indiscriminate of filetypes; it will seek out every file that meets your criteria, regardless of its type. But you can narrow your search immensely--and get much tighter results--if you know before you begin that, for instance, you're looking for an image file or a text document. When you click the All Files and Folders button to see its sub-options, you're confronted with a list of all MIME types registered on your system that also have "friendly" names. Try a query on all files, then try the same query again, but this time pick a specific filetype. Note how much tighter your results are (you may even end up with none).
Query by Attribute Here's where things start to get really interesting. When you switch to searching by attribute, the Attribute drop-down becomes linked to the selected filetype. For instance, if you've chosen to search on the E-mail filetype, the attribute options will be From:, To:, Subject:, etc. If you search on the Person filetype, the attribute options will be phone number, address, and so on. In all cases, however, you'll also get the standard options, such as Starts With, size, modification date, and the other standard options you already get in Mac and Windows finds.
Figure 7.05
When you're searching on a particular filetype and switch to attribute mode, all known attributes associated with that filetype appear as queryable options. These options change automatically whenever you change the filetype. Shown here are the options available when searching on Person files. |
 |
Use Plain English
The BeOS query engine is capable of a few seemingly magical feats when it comes to comprehending your intentions, especially when it comes to modification dates. First of all, it's able to interpret dates written in just about any format. For example, if you want to find files modified after June 7, 1998, you can express that date in any of these ways:
June 7, 1998
06/07/98
7 June '98
06071998
6-7-98
7 Jun. 1998
See Appendix C for a complete list of date and time formats recognized by the BeOS query engine.
But that's not the really cool bit. The query engine is also able to translate dates and times relative to the current time as easily as if you were talking about these times to another human. For instance, all of the following expressions will be interpreted correctly by the query engine:
yesterday
last Friday
last June
day before yesterday
9 days before yesterday
last month
13 days after last month |
Limiting Searches to Specific Volumes To further narrow your search, choose a specific disk volume to query from the picklist at the top right of the Find window. If you already know that the files you seek aren't on your Jaz or Zip disks, for instance, there's no reason to search All Drives. You can select any number of volumes to search from this list by selecting volumes successively. Let's say you have disk volumes named gorgonzola, ghouda, grueyer, and parmesan, and you only want to search on gorgonzola and grueyer. Select one and then the other from this list, and the list's label will change from "All Disks" to "Multiple Disks." The selected volumes will appear with checkmarks by their names so you can see exactly which of your multiple disks are about to be queried.
Querying Custom Attributes
Remember that it's possible to create custom attributes for your BeOS files, and to run queries on them later. However, the attributes you create aren't automatically searchable--you'll need to make sure they make it into the system index first. Complete instructions on adding attributes to the system index can be found in Chapter 5, Files and the Tracker, but to recap, the basic commands are:
- lsindex, which displays a list of all attributes currently being indexed.
- mkindex -t string indexname, which adds a new attribute name to the system index with the type string.
- rmindex attribname, which removes an attribute name from the system index.
So to make sure that your text files' Author attributes are searchable, you'd use:
mkindex -t string TEXT:author
Remember that existing files aren't automatically added to the index--only files created after the index is created will be searchable. |
|
CD-ROMs Slow Down Searches CD-ROMs are second only to floppy disks when it comes to slowness, but the default query mode is to search all mounted BeOS volumes. To improve query speeds, use the Volume picklist in the top right of the Query window to eliminate your CD-ROM from the query process. If you run a lot of queries and don't use your CD-ROM drive very often, don't leave CDs sitting around in your CD-ROM drive. |
Adding Criteria The more details you can provide, the "cleaner" your search results will be. A search on all Person files living in Kentucky doesn't do a ton of good if you have hundreds of them and all you want to find are people who live in Kentucky and also have 1-800 numbers that you can call for free. To further narrow your search, add a second set of criteria by clicking the Add button. There are two modes of adding criteria: "and" and "or". The default mode is "and", which finds only files that meet both of the specified criteria. By changing to "or" mode, you'll find files that meet either the first or second set of criteria. In other words, if you search on people who live in Minnesota and add "starts with "W"," you'll get back only the Person files that match both of these criteria, whereas running the same query in "or" mode will find all files for people who either live in Minnesota or have names that start with "W".
Available Criteria When you search by attribute, your search options change depending on the type of file you're looking for. If you're searching for Person files, you'll be able to construct queries such as "state contains 'CA' & name begins with 'R' or name begins with 'S' & zip code begins with '934'." Similarly, if you're searching on email messages, you'll be able to construct queries such as "sender contains 'Tom' or sender contains 'Louise' & modification date is older than 15 days & status equals 'read'." As shown in Figure 7.05, all attributes registered to a given filetype will automatically appear in the attributes picklist.
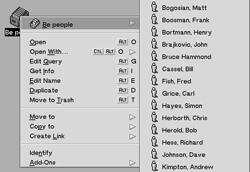
Figure 7.06
Query results are resolved by the Tracker in real time when you right-click a query file icon and select its name from the top of the context menu. Pictured is a query constructed to find Be employees. Rather than digging around in the People folder (or folders) , the query roots them out regardless of their location on the system. Release the mouse over any Person to launch it in the People application. |
 |
Do "Real" File Locations Matter Anymore?
An interesting side effect arises when you start to base a lot of your work on live system queries: The actual location of files on your system becomes less important. For example, if you always look up Person files via query, it suddenly ceases to matter whether you've stored them all in /boot/home/people, in another directory, or scattered all over your system. If the filesystem functions like a database, why bother organizing anything, since queries will pull up the files you want regardless where they live?
While this is theoretically true, and is certainly a nice side effect of query technology, in practice things don't work out that way. For one thing, as discussed in Chapter 5, Tracker views can be customized on a folder-by-folder basis so you can view arrays of attributes in a manner most appropriate to any given directory, and that's not a feature you're liable to be willing to give up. Second, it's just plain old poor housekeeping. Rather than having your person files in all sorts of random locations, it makes sense to store them together in one place so that scripts and other applications can find them easily, and so that you can create clean, uncluttered views of them as a group.
Consider the fact that queries don't care where files live to be a bonus feature, not an excuse to keep a messy hard drive.
Is the Be Filesystem a "True" Database?
If you're at all familiar with databases or database management systems, you've probably noticed many similarities between the capabilities of BFS and those of some common database functions. Queries and found sets, in fact, are central functions of all databases and database management systems. However, BFS isn't built to operate like a high-end relational database, and there is (currently) no way to extract and view the collection of all attributes of all files in tabular format, as you would in a relational database management system. Neither does BFS incorporate any kind of high-end query language like SQL (though Find by Formula is capable of accomplishing most of what SQL's SELECT statement does). There are several reasons for this.
For one thing, the attributes given to your thousands of files are dissimilar from one filetype to the next (Person file attributes share only a single common field with StyledEdit's file attributes, for instance). Therefore, keeping everything "connected" would require the maintenance of an insanely complex relational system, incurring overhead that's better kept out of the operating system itself (this is part of the reason why the true database foundation of the early Be filesystem was abandoned in favor of the current "database-like" filesystem). Second, Be's usual M.O. is to provide an elegant infrastructure in which third parties can develop high-end applications, rather than to provide so much native functionality that some third-party tools are simply unnecessary. For Be to provide that kind of functionality within the operating system itself could curtail demand for development of high-end database products by third parties. Finally, any data collection large and important enough to benefit from the advantages of a real database system would be better stored in a format completely controlled by dedicated applications.
The Same, Only Different
Like a database, the Be filesystem includes collections of named fields containing discrete values. And as with a database, you can mine the system by running powerful queries against attribute fields to extract meaningful information from your file collection. However, BeOS returns its query results in the form of file collections in Tracker windows, rather than as data collections in tables (although with the Tracker's customizability, it comes pretty darn close). Unlike a database, BFS won't let you establish lookup systems or other complex relations between tables. Finally, BFS doesn't do SQL. |
|
Edit Queries Quickly When you're running a query repeatedly and modifying it slightly each time, trying to dial it in to perfection, you don't have to start the query over from scratch each time. Instead, pull down File | Edit Query to pick up where you left off, or use the hotkey Alt+G. |
|
Queries Are Case-Insensitive Queries run from the Find interface are always case-insensitive, even though BFS itself is case-sensitive. In other words, the Tracker will allow you to store files called Williams, williams, and WILLIAMS all in the same folder, as three distinct file names. But when you're looking for a file, there's a good chance you won't remember exactly how its cases are rendered. The query engine does a nice bit of footwork behind the scenes on your behalf so that all instances of your chosen filename are found, regardless of case. If you want to specify case-sensitive queries, use the Find by Formula option described at the end of this chapter. |
Query by Formula The third option on the Query types drop-down--query by formula--is considerably more complex (and correspondingly more powerful) than are standard name and attribute queries. Don't let that stop you from digging into formula queries; they can do some pretty amazing stuff, and they're not that hard to learn. Formula queries are covered at the end of this chapter.
|
The New Index Workaround If you create a new attribute for an existing filetype and you've already got lots of those files, you don't want your searches to be limited by the fact that your new indexes don't log your old files. To get around this quirk, create a temp folder and copy (don't move) all of your old files into it. The act of writing copies to the filesystem will cause their attributes to be added to the index. Once you're sure all your files have actually been copied correctly, you can delete the originals and move the new copies back to the original folder. |
|